In today’s post I’ll cover some of the potential use cases for AWS DynamoDB, why you might want to use it or not.
DynamoDB is fast, highly scalable database service offered by Amazon Web Services. DynamoDB provides table oriented storage of records with variable attributes on each record.
Like any other data storage system DynamoDB has trade offs between its features and capabilities which makes it more appropriate for some applications than others. The point of this post is cover some reasons why (and why not) to use DynamoDB as the database for a project. A way of evaluating the appropriateness of DynamoDB for a project is to first consider could I use it then consider can I use it. The ordering used is to first consider if the system is of any use the project, if it’s not then move on to another technology, SQL Server perhaps? The second consideration is necessary to take into account that in some cases the trade offs that DynamoDB makes may make it inappropriate for applications that it would otherwise work well for.
The below workflow is what we will step through:

First we’ll look at some of things DynamoDB does well and scenarios where DynamoDB’s capabilities would help a project. Things that DynamoDB is good at:
- Predictable speeds: For the most part the potential throughput for a data layer based on DynamoDB is reliable and predictable. Although the pricing and throughput calculations may be hard to figure out initially, once you have the rules you can predict the general throughput cost of an operation and determine the overall IO potential of the system.
- Size scability: Scaling another data storage systems may involve adding volumes, copying data, or adding whole new data node to a cluster (think of SQL Server or Hadoop). Scaling DynamoDB (with one important exception) just involves adding more data to the system. This bullet point could really be rewritten as the advantage of DynamoDB being a PaaS
- A hash based query interface: I mention this item here because it’s the reason my current project uses the service. The query interface gives bulk and single record CRUD access to data stored in DynamoDB. A good analogy that I have often used for DynamoDB is that the query interface gives the client CRUD access to a very large remote hash map (or dictionary). The query end point takes advantage of DynamoDB’s data structure requirements (covered later) to provide very fast access to stored data.
To sum it up DynamoDB is good for situations where fast CRUD performance is required over large and growing data sets. Sounds like:
- Click stream trackers
- Database driven (non-financial) web sites
- Application user session storage
- Staging data storage and de-duplication
We’ll look at some of the trade offs made in using DynamoDB, but let it suffice to say that it should not be used casually. A project considering DynamoDB really needs (at a high level) to have a lot of queries which look like the following in order to justify using it:
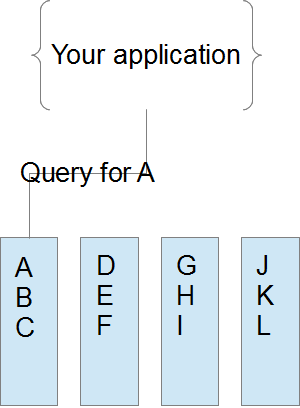 The above picture represents what should be a common query pattern. The application asks for a single or small set of records (ABC) all associated with a single identifier (‘A’ in this case.) If the project is not expected to benefit for high performance single record or small batch CRUD operations then stop here and consider another technology.
The above picture represents what should be a common query pattern. The application asks for a single or small set of records (ABC) all associated with a single identifier (‘A’ in this case.) If the project is not expected to benefit for high performance single record or small batch CRUD operations then stop here and consider another technology.
Second we’ll look at the reasons why DynamoDB might be inappropriate for an application even if it might otherwise provide value. DynamoDB requires a very particular “shape” of data to operate well. Let’s first illustrate with a couple diagrams then discuss what they mean; first hash keys should identify small sets of data like the following:
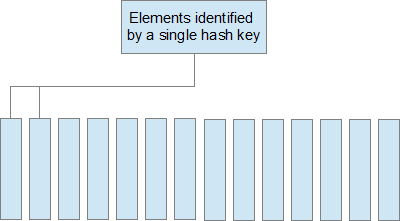 and definitely not like the following:
and definitely not like the following:
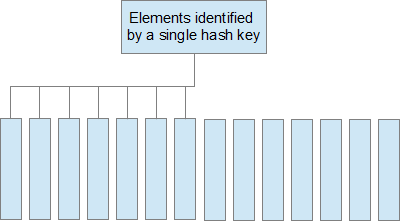 Finally queries into the data set should look like the one above in #1 and not like the following:
Finally queries into the data set should look like the one above in #1 and not like the following:
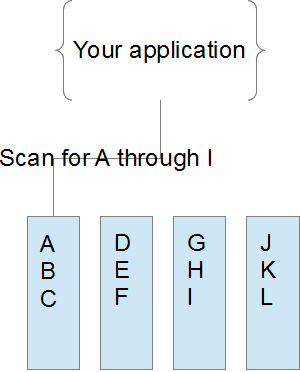 In words the important take away from these diagrams is that data should be stored in small hunks; hash keys in DynamoDB should only identify 1 or a small number of records. Similarly a frequently repeated request should use a hash key to retrieve a small number of records at a time (although there are benefits to batch reads in this case). There are couple reasons why data should be worked with in small ‘hunks’ in DynamoDB.
In words the important take away from these diagrams is that data should be stored in small hunks; hash keys in DynamoDB should only identify 1 or a small number of records. Similarly a frequently repeated request should use a hash key to retrieve a small number of records at a time (although there are benefits to batch reads in this case). There are couple reasons why data should be worked with in small ‘hunks’ in DynamoDB.
- JSON API: The base API for DynamoDB (even if your project uses the Java SDK) is a JSON HTTP interface. For every request to get data from and put data in DynamoDB there is the overhead of de/serializing JSON and making a HTTP request. Serializing and deserializing JSON is not a bad thing in and of itself, but doing it thousands of times is bad if it needs to be done on every request.
- Design Limitations: Placing large data sets underneath any given hash key means that a client application has to sort through all of the data for a hash key to find a needed record. Additionally the use of local secondary indices places hard limitations on the amount of data assocated with any given hash key in the system.
- Load Balancing & Performance: This next point could also be placed under design limitations. The provisioned throughput units in DynamoDB are allocated across hash keys stored in a table. Hot spots where an application very frequently updates or inserts records under the same hash key can lead to poor performance since not all of provisioned throughput for a table is available to any single hash key.
DymanoDB has the above limitations and some others, which leads us to situations where DynamoDB would be an inappropriate choice:
- Data warehousing
- Applications where relationships between data sets must be enforced
Thirdly…should you use DynamoDB?
Maybe, it depends on if your projects would benefit from the good things DynamoDB has to offer and wouldn’t be otherwise be affected by DynamoDB’s weaknesses. Chances are that not everything in a project fits into DynamoDB; only some of a project’s data sets may fit the table store model. I am fan of the idea of polyglot persistence, essentially storing data in different system depending on how it will be used. Since DynamoDB is easy to get started with it’s possible to store the biggest, most IO intensive, UI driving data sets in DynamoDB and then store other project data in different systems. For example on my current project we drive the user interface using DynamoDB in order to make it speedy and take weekly dumps of the data set to load into a relational system for analysis and reporting.